无锁编程简介(翻译)——译自《An Introduction to Lock-Free Programming》
写在前面
本文翻译自经典博文《An Introduction to Lock-Free Programming》,是一篇有关于无锁编程的经典文章。由于译者水平优先,如有谬误实所难免,还请指正。
导入
无锁编程是一个不小的挑战。它不仅难在实现这个任务本身的复杂度,还难在对这个任务自身的理解上。
我很幸运第一次接触到无锁编程的介绍是Bruce Dawson写的博文——《Lockless Programming Considerations》(无锁编程的相关注意事项),这篇文章是一篇完美的读物,且通俗易懂。与其他人一样,我有很多机会将Bruce讲的建议应用到实际的开发和调试工作中,例如Xbox 360平台。
从那时起,市面上陆续出现了许多关于无锁编程的优秀的资料,这些资料涉及了从抽象的理论和正确性的证明到实际的应用和硬件的细节。我也在文末列了一些参考文献。与此同时,我发现很多信息,在不同的资料中甚至会出现混淆的情况:例如,一些材料中假设了顺序一致性的情况,忽略了内存顺序的问题。然而顺序一致性带来的问题,反而是影响C/C++无锁编程的一些代表性问题。C++11标准带来的原子类型标准库也给我们的无锁编程带来了新的挑战,甚至改变了我们许多人对无锁算法的理解。
在这篇文章中,我将重新介绍无锁编程。首先,我会对无锁编程进行定义,然后我会对无锁编程提炼出几个关键的概念。我会利用流程图来展示这些概念之间的相互关系,然后一一对它们进行解释。在开始讲之前,我希望任何一个希望使用无锁编程的程序员都最好已经理解如何使用互斥锁和其他的高级同步工具(例如信号量和消息队列)来编写正确的多线程代码。
什么是无锁编程
人们经常将无锁编程理解为没有互斥锁的编程方式。这是正确的,但是只说了一个方面。基于学术论文中被普遍接受的定义比这要全面一些。从它的本质来说,无锁编程描述的是代码的特性,并不涉及实际代码的编写。
基本上,如果你程序的某一部分代码满足下图情况,则可以认为这部分代码是无锁的。相反,如果你的这部分代码并不满足这些情况,则说明这些代码不是无锁的。
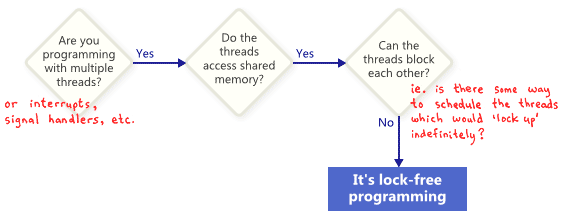
在这里,“锁”并不是简单地指互斥锁,而是代表使整个程序陷入锁住状态的可能性。引起这种情况的原因各种各样,例如死锁、活锁,甚至是你的死对头故意做了一些对你的程序不利的线程调度的决策。最后一种原因听起来很荒谬很可笑,但实际上是可能出现。在某种情况下,共享的互斥锁会被轻易攻破进而造成程序陷入锁住的状态:你的程序的某个线程获取到一个共享锁后,你的死对头可以仅仅再也不调度这个进程从而导致你的整个程序陷入锁住态。当然,这仅仅是我们的一个假想,实际上真正的操作系统并不会这样做。
这里举一个没有互斥锁、但依旧不是无锁编程的例子。刚开始,X=0。作为对读者的一个锻炼,请你们思考一下两个线程怎么来调度使它们都不会退出这个循环。
1 | while (X == 0) |
没有人会期望一个大的应用程序是完全无锁的。一般来说,我们只是希望在整个基础代码中指出一些特殊的无锁操作集合。比如,在一个无锁队列中,它可能会有一个无锁的操作,比如push,pop,isEmpty等等。
《The Art of Multiprocessor Programming》(多处理器编程艺术)的作者Herlihy和Shavit,倾向于把这些操作表示为类的方法,然后得出了关于无锁的如下简介定义:在一个有限的执行中,一些方法的调用一定会有限的结束。换句话说,只要程序能够保持调用这些无锁的操作,结束的操作的数量不管怎样都能保持增加。在进行那些操作时,系统从算法角度来说是不可能把程序锁住的。
无锁编程的一个重要意义是如果你中止了一个线程,它将不会阻止其他组内的线程的操作,因为它们有自己的无锁操作。这也表明了在编写中断处理程序和实时系统时无锁编程的价值,因为在这些情境下,无论系统处于什么状态,一定的任务一定能在一定的时间范围内完成。
最后我们还需要纠正一个概念:被设计来阻塞线程的操作并不会降低算法的质量。比如说,一个队列的出队列操作在队列为空时可能会倾向于阻塞,但其他的代码分支同样可以认为是无锁的。
无锁编程技术
当你尝试在无锁编程中实现无阻塞,有一系列的技术可以实现,例如原子操作、内存屏障、避免ABA问题等。这也是无锁编程变得如此复杂的原因之一。
那么这些技术之间有什么联系呢?为了展示它们的关系,我将它们都画在了下面的流程图中。然后我会详尽地介绍下面地的每一种技术。
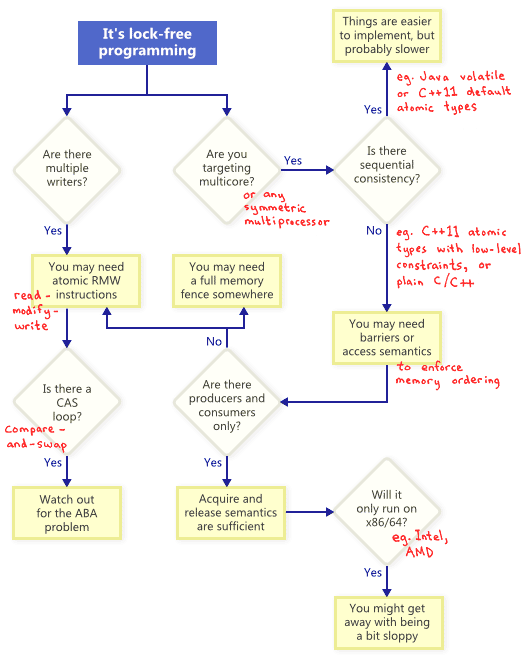
原子RMD(Read-Modify-Write)操作
原子操作是一种不可分割的对内存进行操作的方式——没有线程可以得到完成一半的操作。在现代处理器中,很多操作已经是原子的了,例如对简单数据类型的对齐的读写操作。
RMW操作更进一步允许你去原子地进行更复杂地数据操作。如果一个无锁的算法需要多个写操作时,它们将显得更加有用。因为当多个线程同时在同一个内存地址中尝试RMW操作时,它们能很有效率地排成一队,并分时地执行这些操作。我已经在之前的博文中讨论过RMW操作的应用,例如lightweight mutex(轻量级互斥锁), recursive mutex(递归互斥锁)和lightweight logging system(轻量级的日志系统)。
RMW操作的例子包括Win32下的_InterlockedIncrement,IOS下的OSAtomicAdd32,和C++11下的std::atomic::fetch_add。需要我们注意的是,C++11中,原子操作标准并不保证这个操作在所有平台下都是无锁的,所以最好能够了解你使用的平台是否符合。你可以通过调用std::atomic<>::is_lock_free来确认。
不同的CPU家族有不同的方式来支持RMW操作。像PowerPC和ARM这样的处理器有load-link/store-conditional指令,这将能有效的帮助你在底层实现自己的RMW操作,虽然它不是经常用到。同时,通用的RMW操作一般也是够用的。
就像在流程图中展示的那样,即使在单核系统中,原子的RMW操作也是无锁编程的一个必要组成部分。没有原子性,一个线程可以在执行操作的中途被打断,而这可能会导致不一致的状态。
CAS(Compare-And-Swap)循环
可能讨论最多的RMW操作就是compare-and-swap(CAS)。在Win32中,CAS通过一系列的内联函数来提供,比如_InterlockedCompareExchange。通常,程序员在一个循环中使用CAS来重复尝试一个操作。这个模型典型的操作包括:将一个共享变量复制到一个局部变量中,进行一些特殊的操作,然后尝试使用CAS来修改该共享变量:
1 | void LockFreeQueue::push(Node* newHead) |
这些循环仍然被认为是无锁的,因为如果一个线程的测试失败了,这就意味着它一定在另一个线程中成功了——即使一些体系结构提供了一个差的CAS变体。当进行CAS循环时,特殊需要注意的地方使操作必须防止出现ABA问题。
顺序一致性
顺序一致性表示所有的线程都具有相同的内存操作顺序,同时这个顺序与程序源代码中的执行顺序保持一致。在顺序一致性的前提下,之前博客中出现的内存重新排序的情况就不会出现。
一个简单但不切实际的实现顺序一致性的方法是关掉编译器优化,同时强制要求所有的线程跑在同一核中。在一个核中,即使线程先得到或者随意的线程调度的情况下也不会出现内存乱序的情况。
一些编程语言即使在多核环境下也提供了包括顺序一致性的优化代码。在C++11中,你可以将共享变量声明为C++11中有默认内存顺序限制的原子类型。在Java中,你可以将共享变量声明为volatile类型。这里是用C++11的方式重写的之前博客的例子:
1 | std::atomic<int> X(0), Y(0); |
因为C++11的原子类型保证了顺序一致性,所以结果不可能为r1=r2=0。为了实现这种效果,编译器必须增加额外的指令——内存屏障和/或RMW操作。相比于那些程序员直接处理内存顺序来说,这些额外的指令让应用的执行效率更低。
内存顺序
就像在流程图中所建议的,任何时候你使用多核做无锁编程时,你的环境都不能保证顺序一致性,所以你必须考虑如何防止内存乱序。
在当今的体系结构下,保证正确的内存顺序一般有三种方向,它们能同时防止编译器乱序和处理器乱序:
Acquire semantics能够防止操作指令后面的内存操作乱序,而release semantics能够防止操作指令前面的内存操作乱序。这些操作尤其适合出现生产者/消费者关系的情况,也就是一个线程修改一些信息而另一个线程获得信息。我将会在以后的博客里讨论这个问题。
不同的处理器有不同的内存模型
当出现内存乱序时,不同的CPU都有不同的习惯。规则是由每一个CPU供应商制定的,同时该CPU在硬件上严格地服从这个规则。比如,PowerPC和ARM处理器自己可以改变和指令相关的内存存储的顺序,但是,通常X86/64系列的CPU从英特尔到AMD系列都不能实现。所以我们说前者的CPU应有一个更加自由的内存模型。
这里有一些方案来抽象这些硬件平台相关的细节,尤其是C++11给我们一种标准的方法来写可移植的无所代码。但是现在,我认为大多数的无锁编程程序员都至少有些还在意平台的不同。如果这里有一个最重要的平台不同点需要被记住的话,那一定是在X86/64指令集中,每一次从内存中获得数据会产生一次Acquire semantics,每一次将数据存到内存会产生一次release semantics——至少对无SSE指令和没有写结合操作的内存操作来说如此。所以,以前的无锁代码可以很好的在X86/64平台上运行,但是其他机器中可能会失效。
如果你对硬件怎么实现内存乱序和为什么要有内存乱序感兴趣的话,我建议你看一下附录C中提到的《Is Parallel Programming Hard, And, If So, What Can You Do About It?》(并行编程难么?)这本书。另外你也应注意内存乱序也会由于编译器将指令乱序而出现。
在过去,我很少讲无锁编程的实际应用层面:比如什么时候使用它?我们有多需要使用它?我也很少提到验证无锁代码有效性的重要性。然而,我希望读者们明白的是,这个介绍只是提供了一些基本的无锁编程的概念所以你需要阅读一些其他的资料来进行更加深入的研究。
附加资料
- Anthony Williams’ blog and his book, C++ Concurrency in Action
- Dmitriy V’jukov’s website and various forum discussions
- Bartosz Milewski’s blog
- Charles Bloom’s Low-Level Threading series on his blog
- Doug Lea’s JSR-133 Cookbook
- Howells and McKenney’s memory-barriers.txt document
- Hans Boehm’s collection of links about the C++11 memory model
- Herb Sutter’s Effective Concurrency series